
Proximal Policy Optimization with Continuous Bounded Action Space via the Beta Distribution
Reinforcement learning methods for continuous control tasks have evolved in recent years generating a family of policy gradient methods that rely primarily on a Gaussian distribution for modeling a stochastic policy. However, the Gaussian distribution has an infinite support, whereas real world applications usually have a bounded action space. This dissonance causes an estimation bias that can be eliminated if the Beta distribution is used for the policy instead, as it presents a finite support. In this work, we investigate how this Beta policy performs when it is trained by the Proximal Policy Optimization (PPO) algorithm on two continuous control tasks from OpenAI gym. For both tasks, the Beta policy is superior to the Gaussian policy in terms of agent's final expected reward, also showing more stability and faster convergence of the training process. For the CarRacing environment with high-dimensional image input, the agent's success rate was improved by 63% over the Gaussian policy.
The CarRacing-v0 environment simulates an autonomous driving environment in 2D.

The observation space consists of top down images of 96x96 pixels and three (RGB) color channels. The latest four image frames were stacked and given as input to the agent's network after rescaling and preprocessing them to gray scale (totalling 84x84x4 input dimensions).
The action space has three dimensions: one encodes the steering angle and is bounded in the interval [-1, +1]. The other two dimensions encode throttle and brake, both bounded to [0, 1].
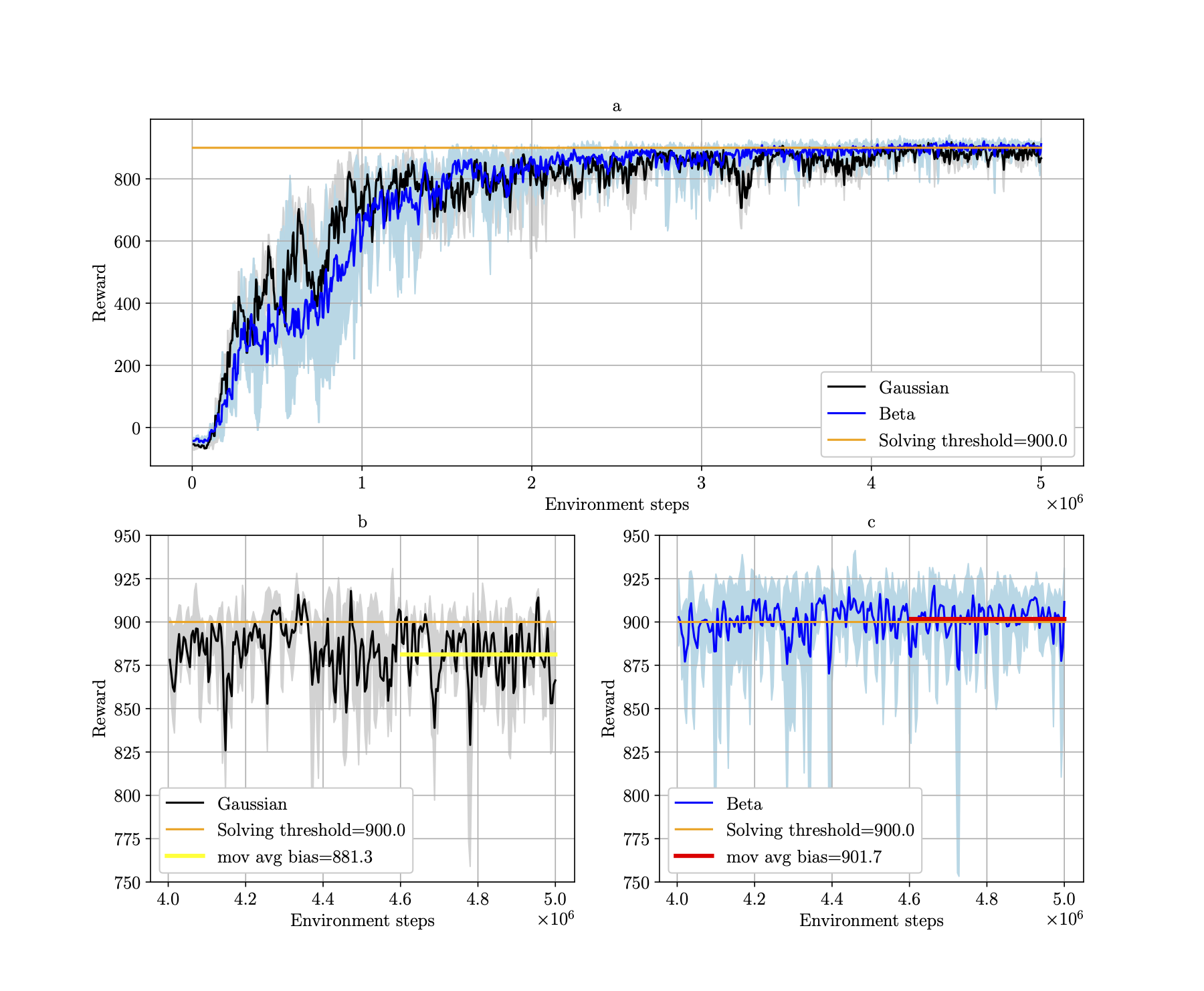
In the plot below, we can see the average rewards for 5 agents with different seeds for the CarRacing environment.
The final performance is shown on the bottom plots at a bigger scale, for agents with Gaussian policy (bottom left) and Beta policy (bottom right).
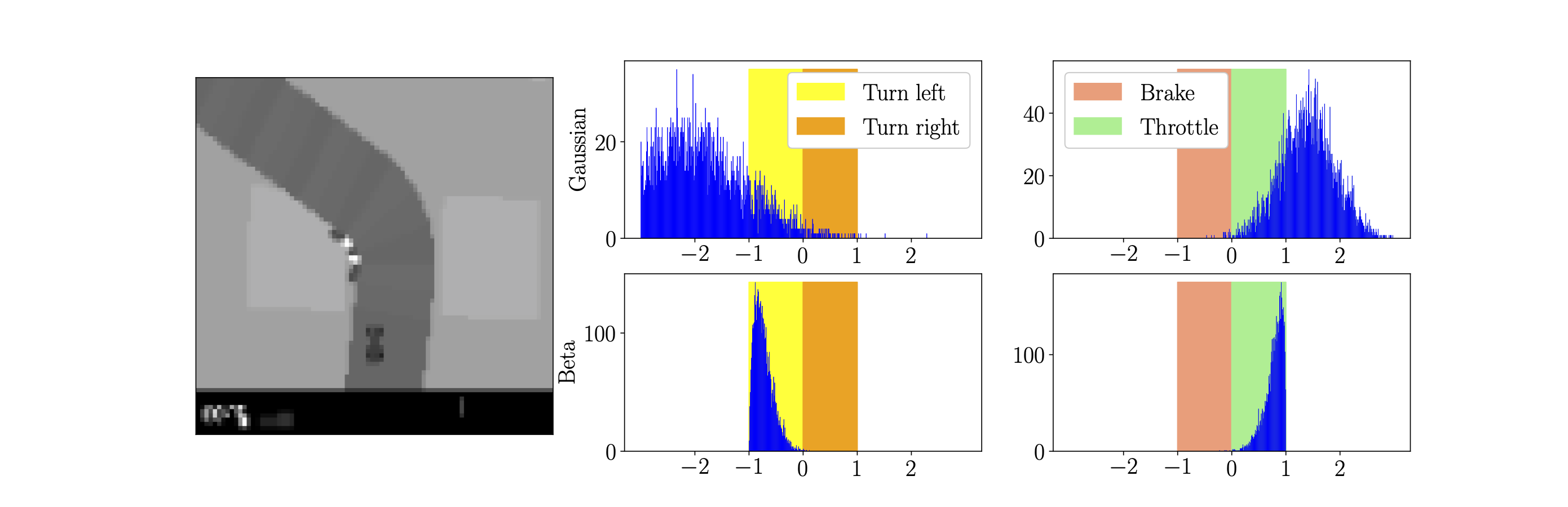
Next, we see an illustration of the Gaussian and Beta stochastic policy distributions in relation to the action space of the CarRacing environment.
For a fixed observation s (preprocessed image in left plot), we sampled the Gaussian and Beta policies for 5000 actions.
For the Gaussian distribution, a significant portion of the actions fall out of the valid direction and brake/throttle range (both [-1, 1]), whereas for the Beta distributions, all actions fall within boundaries.
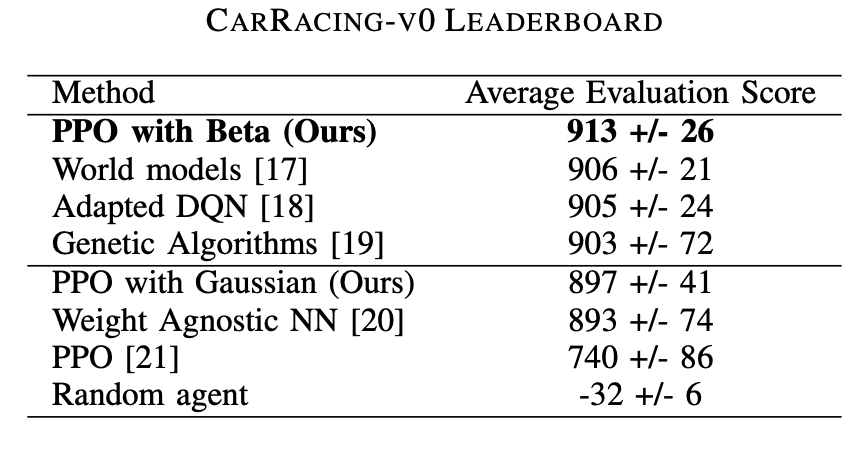
OpenAI CarRacing-v0 Leaderboard hosts a series of self-reported scores. We compare our results only to those found in peer-reviewed articles since they provide a basis for comparison and discussion.
Our proposal currently (as of 2021) surpass state-of-the-art models, beating all work reported previously in the literature.
Tag:
Research area:
Autonomous Vehicles